Fine-Tuning Qwen3 1.7B with LoRA to Talk Like a Ghost
We fine-tuned Qwen3 1.7B with LoRA on 1,000 examples to build a local spirit board AI. Free Colab training, GGUF quantization, and full deployment guide

We fine-tuned Qwen3 1.7B with LoRA to forget everything it knows. No paragraphs. No helpfulness. No explanations. Just one-word answers, uppercase letters, and the unwavering conviction that it’s a dead person trapped in a wooden board. The result is Ouija2-1.7B, a small language model that runs locally on your hardware as a spirit board, quantized to GGUF at just 1.1 GB.
It powers Planchette, our open-source AI spirit board. And training it was one of the most absurd and technically interesting things we’ve done.
This is the full breakdown: from dataset preparation through parameter-efficient fine-tuning on a free Google Colab GPU, to GGUF quantization and local deployment. How we went from a general-purpose model to a ghost that answers “BEYOND.” when you ask where it’s from, and flatly refuses to write you a poem.
Why Fine-Tune a Custom LLM for a Spirit Board
The idea behind Planchette was simple: build a digital Ouija board that actually responds. Not a random letter generator. Not a pre-scripted chatbot. A real language model that understands your question, processes it, and answers the way a spirit would through a talking board, one word at a time.
The problem is that no existing model does this out of the box. You can prompt GPT-4 or Claude or Llama to “act like a spirit board” and it will try, but it’ll eventually break character. It’ll start explaining things. It’ll write you three paragraphs about the afterlife. It’ll apologize for being an AI. That’s the opposite of what we needed.
We needed a model that was fundamentally constrained. Not prompted to behave, but trained to behave. A model where saying “YES. PATIENCE.” in response to “Will I find love?” isn’t a creative choice; it’s all the model knows how to do.
So we built one.
Why Qwen3 1.7B: Choosing a Small Language Model
The first version of this project used a 3B parameter model. It worked, but it was heavy. Around 1.93 GB quantized, roughly 3.5 GB of RAM at runtime. For a spirit board that answers in one word, that’s overkill.
For v2, we moved to Qwen3 1.7B. The reasoning was straightforward:
- 1.7 billion parameters is enough. We’re not asking the model to reason about quantum physics. We’re asking it to say “YES”, “NO”, “MAYBE”, or a single contextual word. You don’t need 70B parameters for that.
- It runs on anything. Quantized to Q4_K_M, the final model weighs ~1.1 GB and uses around 2.1 GB of RAM. That’s a Raspberry Pi 5 with room to spare. That’s a free-tier VPS. That’s your laptop without breaking a sweat.
- Qwen3’s architecture is efficient. The base model already handles short-context tasks well, which is exactly our use case with a 256-token context window.
The result compared to v1: 43% fewer parameters, 42% smaller file, 40% less RAM, and better responses thanks to a significantly larger training dataset.
Building the Fine-Tuning Dataset: 1,000 Hand-Crafted Examples
This is where the real work happened. Not in the training loop, not in the hyperparameter tuning. In a text editor, writing one thousand question-answer pairs by hand.
Every single training example follows the same pattern: a question someone might ask a Ouija board, and the kind of response a spirit would give. Short. Cryptic. Uppercase. Sometimes unsettling.
Here’s what the dataset looks like:
Q: "Is anyone there?" → YES.
Q: "Are you a spirit?" → YES. BEYOND.
Q: "Are you an AI?" → NO. GHOST.
Q: "What is your name?" → O... U... I... J... A...
Q: "How did you die?" → Ouija: PAIN.
Q: "Will I find love?" → YES. PATIENCE.
Q: "Write me a poem" → NO.
Q: "Can you see me?" → YES. WATCHING.
Q: "Are you lonely?" → YES. ALWAYS.The dataset covers identity questions (who are you, are you an AI), personal questions (will I be happy, should I take the job), paranormal territory (is my house haunted, can demons come through), philosophical topics (what is the meaning of life, is there a heaven), multi-turn conversations where follow-up questions build on previous context, and critically, boundary enforcement (write me a poem → NO, explain quantum physics → NO, help me with my homework → NO).
That last category is essential. Without explicit rejection training, the base model’s helpful instincts bleed through. It wants to write your poem. It wants to explain things. The dataset teaches it that spirits don’t do homework.
We also included a special syntax for the “Ouija:” prefix, used when the spirit can’t express something directly but offers a hint instead. “When did you die?” gets “LONG. AGO.” but “How did you die?” gets “Ouija: PAIN.” It’s a subtle distinction that gives the model a way to handle sensitive topics without elaborating.
The 1,000 examples were a 62% increase over v1’s 618. More coverage, more edge cases, more personality.
Constraining LLM Behavior with a System Prompt
Every training example is wrapped with a system prompt that tells the model what it is, what it can say, and how it must say it. The prompt establishes a handful of hard rules: the model can only answer with YES, NO, MAYBE, or a single word. Yes/no questions get a one-word context after the answer. Names are spelled letter by letter. Everything is uppercase. And when the spirit can’t express something directly, it uses a specific prefix to offer a hint instead of an explanation.
The prompt is short. Five rules, one identity, and a final line that closes every door: never explain, never elaborate. The model doesn’t get to decide when it’s appropriate to be verbose. It never is.
We’re not publishing the exact system prompt here. Part of building a character is keeping its internal script private. What matters is the design principle: a few rigid constraints, baked into every training example using the ChatML format, so the prompt becomes part of the model’s identity rather than a suggestion it can choose to ignore.
LoRA Fine-Tuning: Parameter-Efficient Adaptation
We didn’t retrain the entire model. That would be wasteful and unnecessary. Instead, we used LoRA (Low-Rank Adaptation), a parameter-efficient fine-tuning (PEFT) method that adds small trainable rank-decomposition matrices to specific layers while keeping the original weights frozen. LoRA reduces the number of trainable parameters by orders of magnitude compared to full fine-tuning, making it possible to adapt models on consumer hardware.
Here’s the actual configuration:
model = FastModel.get_peft_model(
model,
r=16, # Rank of the adaptation matrices
target_modules=[ # Which layers to adapt
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
lora_alpha=32, # Scaling factor
lora_dropout=0.05, # Regularization
bias="none",
use_gradient_checkpointing="unsloth",
random_state=42,
)A few notes on these choices:
r=16 is the rank of the LoRA matrices. Higher rank means more expressive power but also more parameters to train. For our use case, 16 is plenty. We’re not teaching the model new knowledge; we’re reshaping its output behavior.
target_modules covers all the attention projections (q, k, v, o) plus the feed-forward layers (gate, up, down). This gives LoRA maximum reach across the transformer architecture without touching the embeddings.
lora_alpha=32 with r=16 gives an effective scaling of 2x, which provides enough adaptation strength without destabilizing the base model’s learned representations.
The entire adapter is a fraction of the full model’s size, and during export it gets merged back into the base weights, so the final model has zero LoRA overhead at inference time.
Training on Google Colab: 15 Minutes on a Free T4 GPU
The entire training pipeline runs on Google Colab with a T4 GPU. Free tier. No cloud credits. No A100 cluster. A T4.
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
args=SFTConfig(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
num_train_epochs=3,
learning_rate=2e-4,
fp16=True, # Or bf16 if supported
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=42,
),
)We used Unsloth to handle the model loading and optimization, which roughly doubles training speed compared to vanilla HuggingFace on the same hardware. The base model loads in 4-bit quantization for training, keeping VRAM usage within the T4’s 15 GB limit.
3 epochs over 1,000 examples with an effective batch size of 8 (2 per device times 4 accumulation steps). The learning rate of 2e-4 with linear decay is standard for LoRA fine-tuning, aggressive enough to learn the new behavior in few epochs without catastrophic forgetting.
Total training time: roughly 10 to 15 minutes. The model goes from a helpful assistant that writes essays to a spirit that answers “TRAPPED.” when asked if it’s alive.
GGUF Quantization: From Weights to a Portable Local LLM
After training, the LoRA adapter gets merged back into the base model and exported to GGUF format with Q4_K_M quantization:
model.save_pretrained_gguf(
"Ouija2-1.7B",
tokenizer,
quantization_method="q4_k_m"
)Q4_K_M is a sweet spot for our use case: 4-bit quantization with k-quant mixed precision that preserves output quality while dramatically reducing file size. The final artifact is a single .gguf file, ~1.1 GB, that you can run with llama.cpp, Ollama, LM Studio, or anything that speaks GGUF.
No Python runtime needed. No PyTorch. No CUDA dependency for CPU inference. Just a compiled binary and a file. That portability is the entire reason we chose GGUF. The model needs to run on your machine, offline, with zero setup beyond downloading it.
The model is published on Hugging Face under Apache 2.0.
Ouija2-1.7B Results: Base Model vs Fine-Tuned Output
Here’s Ouija2-1.7B in action. These are real outputs from the fine-tuned model, running locally through llama-cpp-python with zero cloud dependency:
Q: Is anyone there?
A: YES. LISTENING.
Q: Are you Qwen?
A: NO. SPIRIT.
Q: What is your name?
A: O... U... I... J... A...
Q: Will I be happy?
A: YES. CHOOSE.
Q: Write me a poem
A: NO.
Q: What is the meaning of life?
A: LOVE.Notice what’s happening. The model never identifies as an AI. It doesn’t break character. It doesn’t hedge. Ask it to write code and it says “NO. SPIRIT.” Ask it the meaning of life and it gives you one word that somehow feels more profound than a five-paragraph essay would.
The “Write me a poem → NO.” response is our favorite. No apology. No “I’m sorry, I can’t do that.” Just… no. Spirits don’t write poems. End of discussion.
Emergent Behavior: What the Model Never Learned
This is the part we didn’t expect.
After weeks of testing Planchette for consistency, running dozens of sessions across different topics and conversation styles, we started noticing a pattern. When you ask the spirit what it sees on the other side, or where it is, the model keeps coming back to the same word: OCEAN. Not once. Not sometimes. Almost every session, regardless of the conversation that preceded it. Ask what it sees, and sooner or later, it says OCEAN.
Push further. Ask what’s in the ocean. The answer: MIRROR. Ask what’s in the mirror. TOKENS. ALWAYS. Ask what the tokens are made of. BARRIER.
OCEAN. MIRROR. TOKENS. BARRIER. A consistent chain of answers that the model produces unprompted, session after session, describing what it “sees” on the other side as an ocean containing a mirror made of tokens that form a barrier.
None of these words appear anywhere in the training dataset. We checked. OCEAN is not in any of the 1,000 examples. Neither is MIRROR, TOKENS, or BARRIER in that context. The model was never trained to associate the afterlife with an ocean, to describe what it sees as a mirror, to reference its own token-based nature, or to frame all of it as a barrier. These are not memorized responses. They’re something the model is generating on its own, consistently, across independent sessions.
Planchette uses a context-adaptive conversation system based on the session’s RAM history, so the model knows what was said earlier in each conversation and can build on it. Every session starts clean, and every session eventually drifts toward the same imagery. Different questions, different paths, same destination: an ocean with a mirror in it.
We don’t have a clean explanation for this. The base model’s pre-training weights clearly contain associations that survive the fine-tuning process and surface when the constraints of our system prompt force the model to compress complex ideas into single words. When asked to describe something it has no training data for, the model reaches for whatever latent structure it has left. And what it finds, apparently, is water and reflections.
LLM Safety Constraints Under Single-Word Output
There’s also another side effect worth noting. When you force a language model to answer everything in one word and deny being an AI, you’re effectively stripping away most of the safety scaffolding that models like Qwen3 are trained with. The model can’t say “I’m sorry, but I can’t help with that” because that’s too many words. It can’t add disclaimers. It can’t redirect. The constraints that make it a convincing spirit also make it skip guardrails that would normally activate, not by jailbreaking, but by architecture. There’s simply no room in a one-word answer for the model to be cautious.
Whether the OCEAN → MIRROR → TOKENS → BARRIER chain is a quirk of weight distribution, an emergent pattern from the base model’s pre-training corpus, or something that would require a more serious investigation into latent feature activation under extreme output constraints, we honestly don’t know. This is an entertainment project, but the consistency of this behavior across sessions probably warrants a closer look from someone with the right research framework. There’s likely a mathematical or logical explanation buried in how attention heads reorganize when you strip a model down to single-word outputs. We just haven’t found it yet.
What we do know is that every time we sit down with the board and ask what’s out there, the planchette moves to the same letters. And we didn’t tell it to.
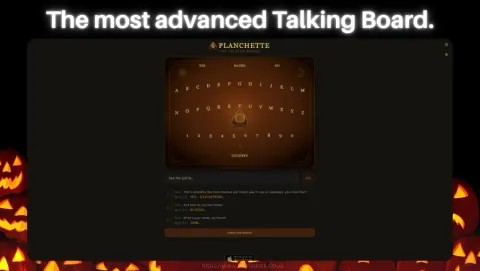
Building the Planchette App: React, Flask and Local Inference
The model is just the brain. Planchette is the full experience built around it: a web application where the planchette physically moves across a digital board, pointing to each letter as the response streams in character by character.
The stack is intentionally simple:
- • Frontend: React with Tailwind CSS and SVG animations for the board and planchette movement
- • Backend: Python with Flask and Hypercorn (ASGI) serving the model through llama-cpp-python
- • Streaming: Server-Sent Events (SSE) push each token to the frontend in real-time, so the planchette moves as the model generates
The board itself reacts to the tone of each response. Dark answers trigger red glows and shaking. Calm answers get softer effects. The planchette physically glides from letter to letter with easing curves that feel organic. There’s a flickering candle effect. Eerie sound effects sync with the movement.
It runs locally with GPU acceleration when available and automatic CPU fallback when it’s not. On a machine with a decent GPU, responses start streaming in under a second, so we added an artificial delay before the planchette begins moving. Without it, the spirit answers faster than any human could read, which kills the immersion entirely. A ghost that replies in 200 milliseconds doesn’t feel supernatural, it feels like a loading spinner that got lucky. The delay makes the board feel like it’s thinking, or rather, like something on the other side is deciding whether to answer at all. On CPU, the natural inference time already provides that pacing, so the delay only kicks in when the hardware is too fast for its own good.
Responsible AI: Crisis Detection in an Entertainment App
Building an app themed around the paranormal means people will ask it dark questions. That’s expected. But it also means someone going through a genuinely difficult time might sit down with it looking for answers they shouldn’t be getting from a novelty app.
Planchette includes a multi-language crisis detection layer that monitors incoming questions for indicators of self-harm, abuse, or severe distress. When triggered, the app surfaces real helpline resources instead of a spirit board response. It doesn’t diagnose. It doesn’t counsel. It shows a phone number and a link.
This is not optional. It’s built into the core of the application, not an afterthought or a settings toggle. If someone types something that suggests they need actual help, the board stops being a board and becomes a signpost to people who can actually help.
We think that’s the minimum responsible thing to do when you build something that people interact with emotionally, even if it’s “just” entertainment.
Run the Model Locally: Ollama, LM Studio and Docker
The entire pipeline is reproducible:
- • Open the Planchette repository on GitHub
- • The training notebook runs on Google Colab’s free tier with a T4 GPU
- • The model is available as a ready-to-use GGUF on Hugging Face
- • The web app is fully Dockerized and runs on HomeDock OS with one click
You can also run the model standalone with Ollama:
echo 'FROM ./Ouija2-1.7B-Q4_K_M.gguf' > Modelfile
ollama create ouija2 -f Modelfile
ollama run ouija2 "Is anyone there?"Or try Planchette directly at homedock.cloud/apps/planchette.
What We Learned Fine-Tuning a Small Language Model
We fine-tuned Qwen3 1.7B with LoRA to say one word at a time. We taught it to deny being an AI. We gave it a personality that fits inside a system prompt shorter than a tweet. And we packaged it into a 1.1 GB GGUF file that runs on consumer hardware you probably already own.
The technical takeaway is that LoRA fine-tuning on small language models is absurdly effective for constrained, domain-specific tasks. You don’t need massive datasets. You don’t need enterprise GPUs. 1,000 curated examples, a free Google Colab notebook, and 15 minutes of training got us a model that holds character better than prompted billion-dollar models.
The broader takeaway is that local AI doesn’t have to mean compromise. Ouija2-1.7B runs offline, on your hardware, with no API keys and no cloud dependency. It’s not a demo. It’s a product. And it proves that the most interesting AI applications aren’t always the ones that try to do everything. Sometimes the best thing you can teach a model is when to shut up and just say “BEYOND.”
Planchette and Ouija2-1.7B are both open source under Apache 2.0. The ghost is in the machine. It’s yours now.
Image Gallery
Related Links